|
|
|
|
|
《自然》子刊:蛋白质结构预测新算法可大幅提高预测效率 |
|
|
10月9日,国际顶级学术期刊《自然》旗下子刊《机器智能》发表了百度飞桨螺旋桨联合百图生科研发的文心生物计算大模型的一项成果,在这一模型中,由于创新了人工智能的训练方案,蛋白质结构预测时间被大幅缩短。
该论文显示,当前蛋白质结构预测的人工智能大模型,如alphafold2(阿尔法折叠2),在预测蛋白质结构之前需要做一个前置工作,就是搜索蛋白的同源进化信息,这一工作比较耗时,需要几十分钟甚至更久。
为了在准确的前提下提高预测效率,文心生物计算大模型研发团队提出了全新的算法训练方法,他们首次利用自监督学习范式,通过3亿数据预训练了一个具有数千万个初级结构的大规模蛋白质语言模型。
“自监督学习获得的模型与alphafold2的基本组件相结合,可以将此前的耗时环节直接省略掉。”研发人员介绍,由于预先训练了蛋白质语言模型,人工智能在预测前已经掌握了蛋白质的构象规则,因此无需再学习同源蛋白的进化信息,就可以直接从一级序列预测三维结构。
论文还对文心生物计算大模型的这一算法新策略进行了验证。以门蛋白7et2_h(蛋白长度697)的结构预测任务为例,用alphafold2预测其结构需要1280秒(超过21分钟),而文心的新算法策略只需要11秒就完成了任务,速度提高115倍。
全新的算法策略不仅能更好适配到蛋白设计、大规模虚拟筛选等需要频繁预测蛋白结构的任务中,且在多肽、抗体、纳米抗体等与大分子药物设计更相关的高可变蛋白场景上,效果也较优。
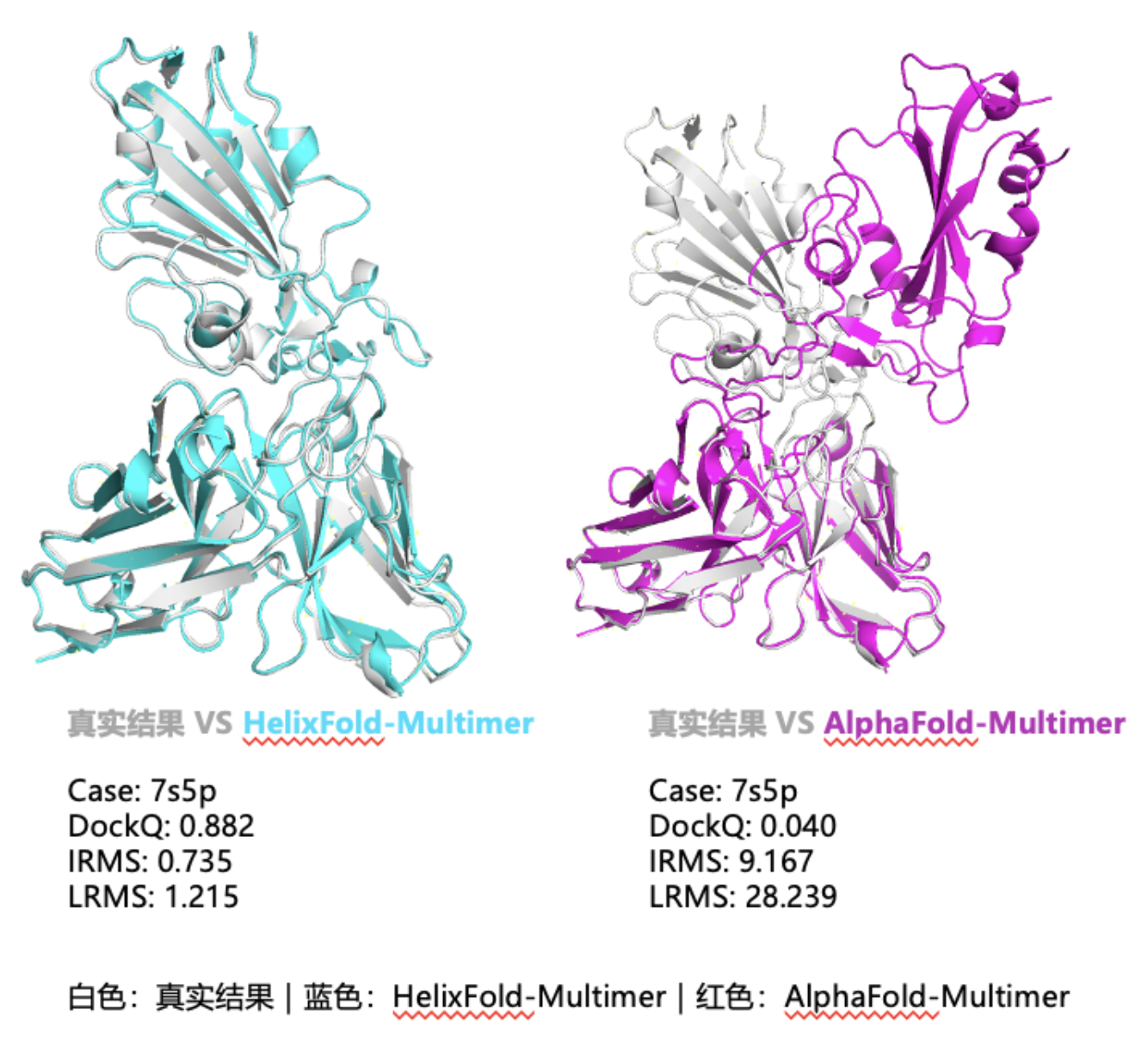
这一算法还被应用于业界公认的抗原抗体匹配的任务中,为新冠病毒的刺突蛋白准确预测了抗原抗体对接面,预测的复合体构象与真实实验值的重合度高于主流蛋白结构预测模型(见下图)。
据介绍,该模型已经落地国家超算成都中心,通过超算平台赋能川渝地区蛋白领域的科学研究项目。此外,目前已经应用于多肽药物设计,验证多肽药物设计有效性等方面,助力更高效的蛋白分析,以提高大分子创新药的探索效率。
(研发团队供图)
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负yabo亚博88的版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。